 14 DAY TRIAL //
14 DAY TRIAL // The most secure system up to date has been recently shown to be much more vulnerable than previously thought. This has triggered a call for the development of a mathematical theory able to show why some codes can be cracked more easily than others.
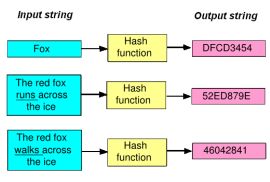
At the foundation of data security today is a so-called "hash function". This function transforms an input string of arbitrary dimensions (be it an 8-character password or a 1000-page document) into an output string of fixed length. The point is that if the input string changes in some way (e.g. "The red fox runs across the ice" changes into "The red fox walks across the ice") than the output string should also change. This way, one can easily and at great speeds detect whether large documents or files have changed by checking the changes in the output strings.
It is pretty obvious that any hash function will have many different input strings going into the same output string. However, the question is: How difficult is it to find an alternative input string that would foul the hash function? For example, how difficult is it to create a password generator - a program that would generate various passwords that will all work?
Thus, these "hash function" are central in the design of cryptographic systems that protect electronic communications. Susan Landau, in her paper "Find Me a Hash", calls hash functions the "duct tape" of cryptography because they are used everywhere for many different purposes: to authenticate messages, to ascertain software integrity, to create one-time passwords, in digital signatures, and to support many Internet communication protocols. The very ubiquity of hash functions makes any vulnerability found in them a widespread concern.
She writes: "Ten years ago, there was a need to replace the Data Encryption Standard (DES), the encryption algorithm with a 56-bit key that had been functioning since the 1970s. Fortunately, since the 1980s there had been fundamental research into the design of block ciphers, much of it from ideas learned through attacks on DES. The strength of the Advanced Encryption Standard (AES), approved as a Federal Information Processing Standard (FIPS) in 2002, is based on that research. It is clear that we need new hash functions, but hash research is not in the same place as block ciphers were a decade ago. Until we really understand the underpinnings of secure hash functions, it does not make sense for National Institute of Standards and Technology (NIST) to begin a serious competition for the next one. DES, a good algorithm for developing an understanding of the security of block-structured ciphers, provided practice for cryptanalysts. SHA-256 [the most advanced 'Secure Hash Algorithm' insofar] is probably the right place to start to do the same for secure hash functions. What is the theory of hash functions? It is not often that mathematicians are asked to develop a theory for duct tape, but there is a clear and present need to do so now for cryptographic hash functions."
Currently, the most widely used algorithm is the SHA-1. Cryptographers were amazed at a meeting last year when it was shown that SHA-1 is much more vulnerable than previously thought. Other older and even less secure hash algorithms are still in use in many applications. Although SHA-1 is still considered safe because the necessary resources needed to crack it are fairly large, there is an urgent need to replace it. The SHA-256 is available but it takes time for it to be deployed throughout the entire infrastructure.
However, as Susan Landau said, in order to get to the next level of new and better hash functions, one needs to understand in more detail the underlining mathematical theory - which insofar does not exist. So, there is a call for next Alan Turing.