14 DAY TRIAL //
14 DAY TRIAL // If you have any sort of interest in NVIDIA and supercomputers, or just one or the others, you probably already know at least a few things about the Tesla series. It's that product series that is getting updated today.
Since the time has expired for what was most definitely not a gag order (officially anyway), we can finally share with you all the awesome things we've learned about NVIDIA's latest contribution to the Supercomputing front, what you might know as HPC as well (the high-performance computing market).
The Santa Clara, California-based company has completed development of the Tesla K80 GPU compute accelerator.
The specs of Tesla K80
As odd as it sounds, NVIDIA didn't share this information with us. While it did hold a conference call on the matter last Thursday, it didn't offer many technical details about the adapter.
We do know some things though. For example, there are 4,992 CUDA cores, thanks to the use of two GK210 graphics processing units.
Yes, NVIDIA did make a new GPU just for this card, and no, NVIDIA did not use the Maxwell architecture. Several of us who attended the call asked if there were plans for Maxwell-based Tesla cards now or in the future, but NVIDIA stayed evasive on that front.
You did read the CUDA number right though. It really is a smaller number of cores than on the GeForce GTX Titan dual-GPU gaming monster (which has 5,760).
I actually asked how the board compared to a GTX Titan Z, but the answer was somewhere along the lines of “it wouldn't be a relevant comparison.”
It probably had something to do with the clocks being a secret as well, although the NVIDIA rep did speculate that they could be of around 790 MHz base and 875 MHz GPU boost. Don't quote us on this though.
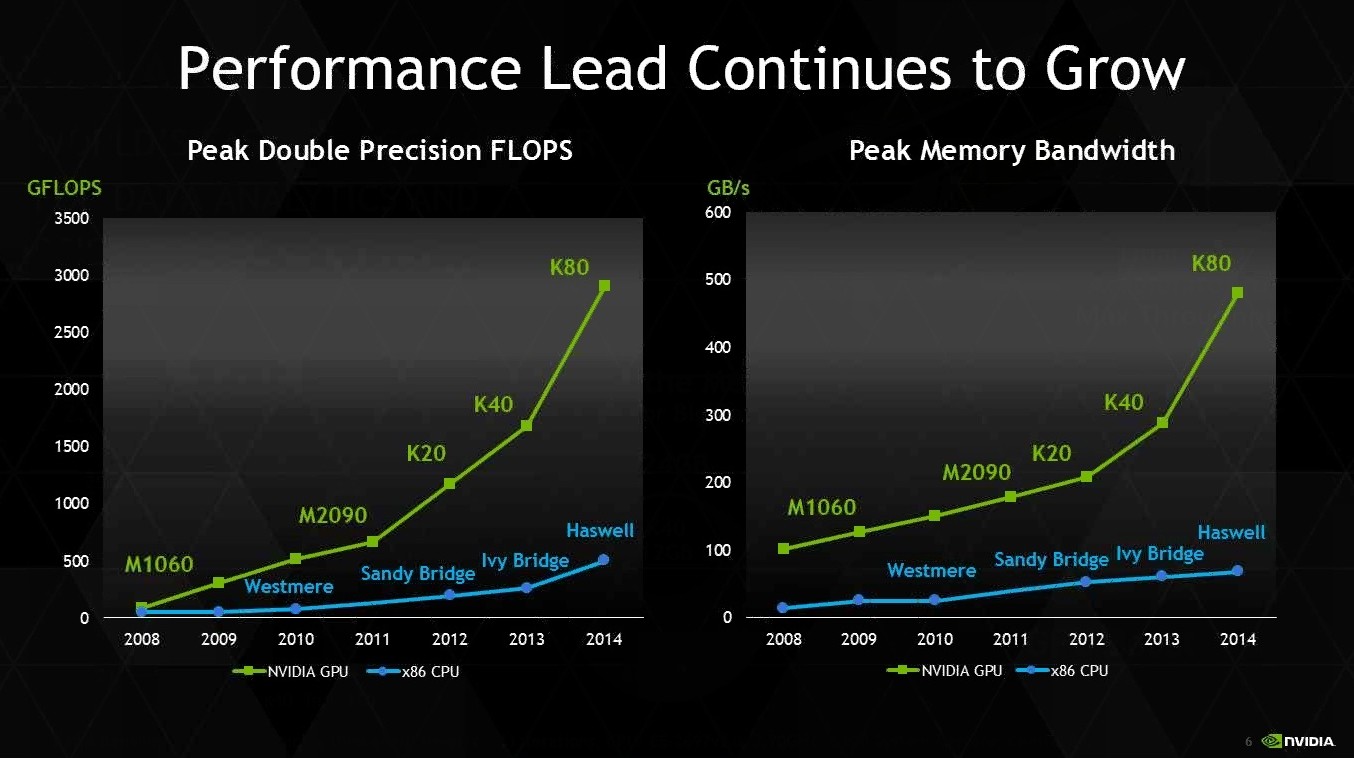
That said, the Tesla K80 has a TDP of 300W, 1.87 TF to 1.9 TF performance (with boost enabled) and no fewer than 24 GB of GDDR5 VRAM. All this leads to a bandwidth of 480 GB/s.
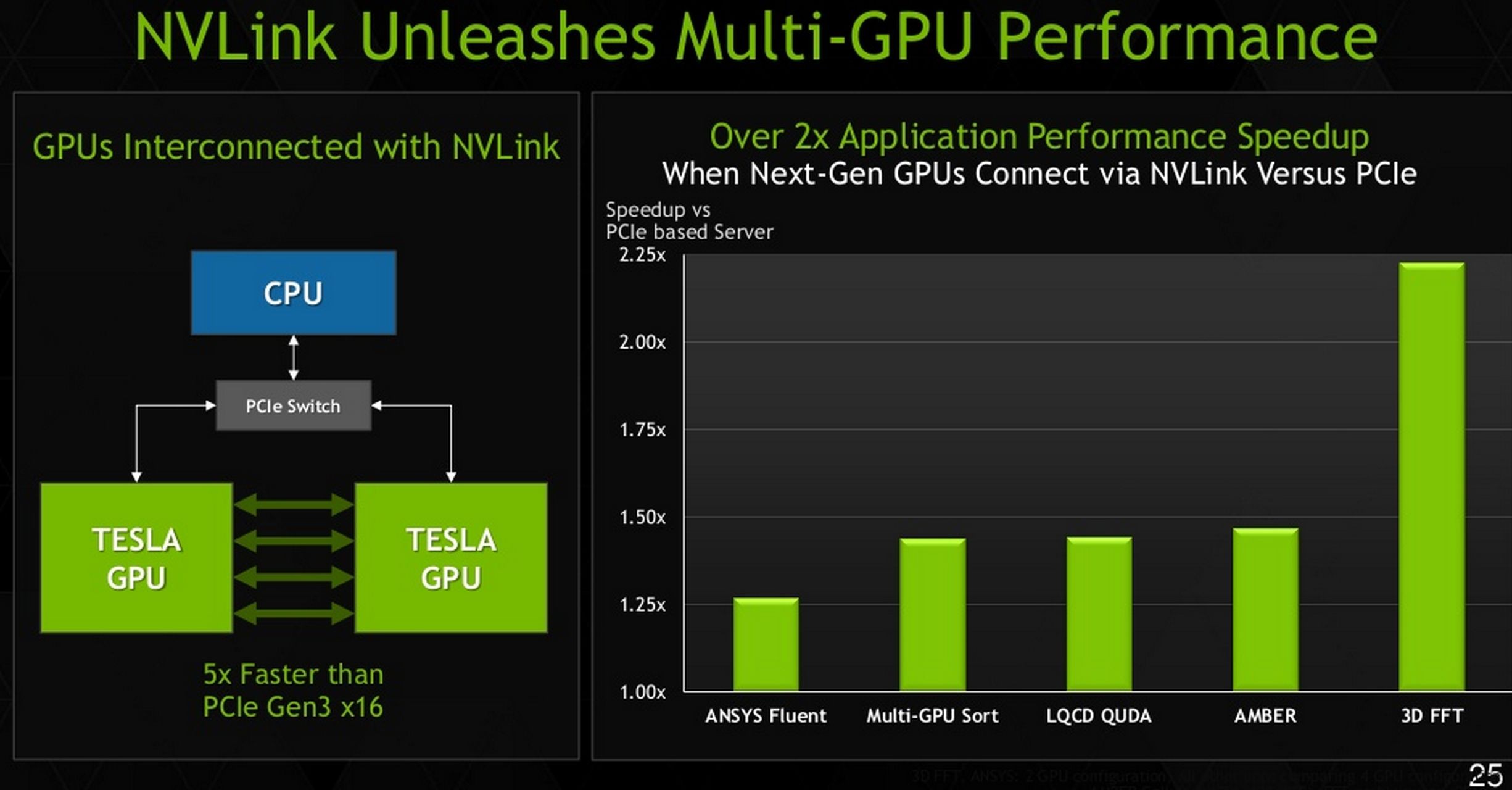
NVIDIA reveals NVLINK technology
Given how the conference call went, we could probably be accurate in saying that NVIDIA is more excited about this technology than the card itself.
At previous product announcements, NVIDIA allowed a system to directly access GPU resources without having to go through the OS first, and to some extent without having to ask the GPU either.
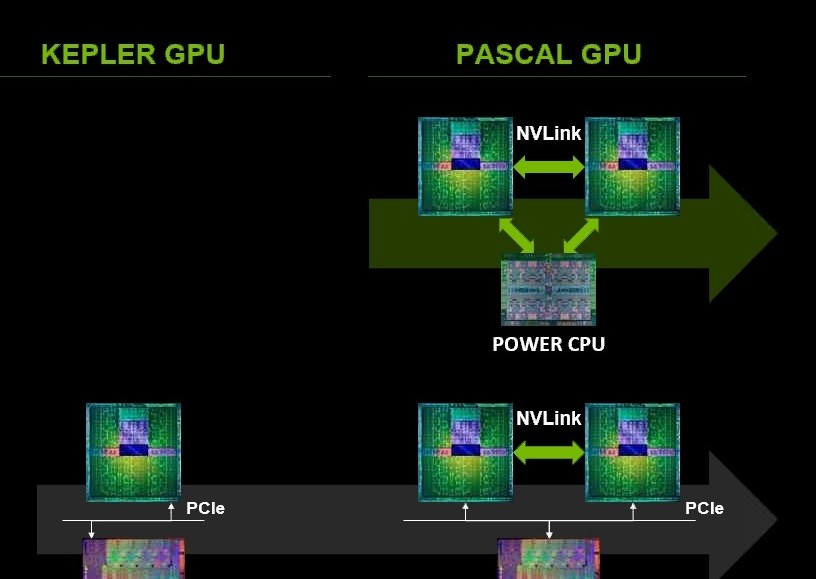
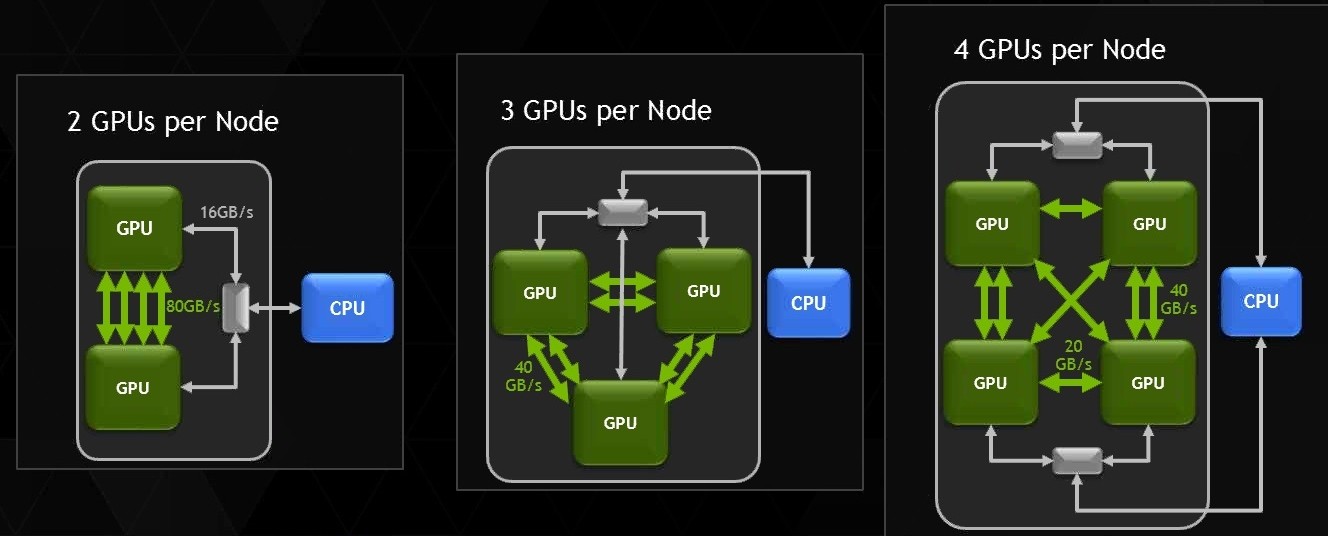
NVLINK is a new technology that allows multiple GPUs in a system to connect to one another directly, via one or more 20 GB/s links. With each GPU having four links and up to four GPUs supported in one NVLINK system, that leads to a lot of bandwidth. Currently, the top is of 200 GB/s, allowed by 4-GPU nodes, but 3-GPU and dual-GPU nodes are possible as well. Possibly more than four in the future, but again NVIDIA didn't say one way or the other.
Either way, with 2,046 in-site GPU nodes per supercomputer, everything points towards a lot of performance.
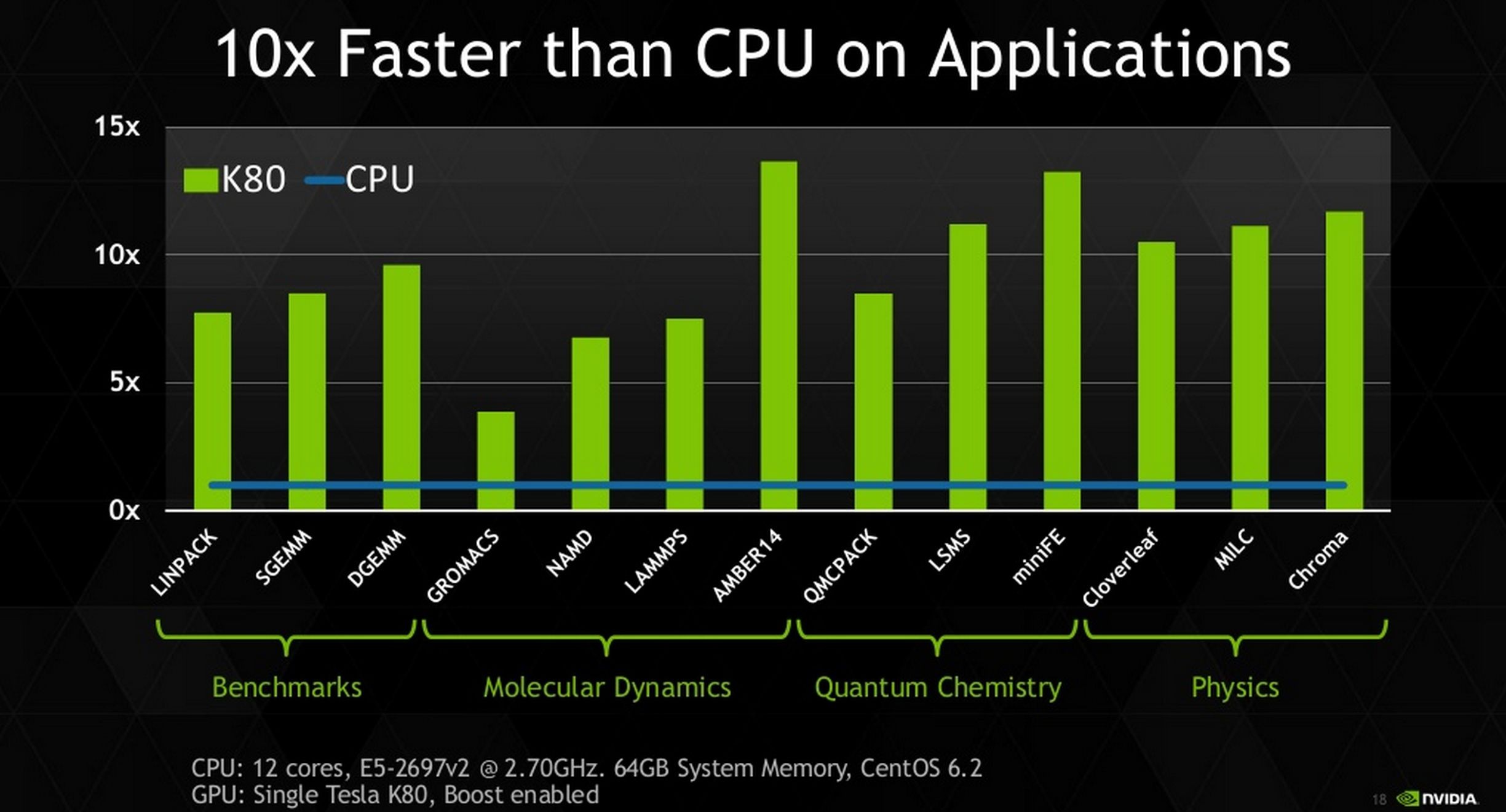
Practical applications for the NVIDIA Tesla K80
As long as it's a powerful supercomputer you want to build, it doesn't matter what you have it do. Tesla K80 can definitely crunch numbers like crazy. During the call, NVIDIA said that no Top500 HPC systems can be announced yet, but a more recent announcement suggests that the Tesla K80 will be used in the Titan 2, the successor to the current strongest supercomputer ever.
The computing power will be triple that of the current available one. It'll be years before we see it in action though.